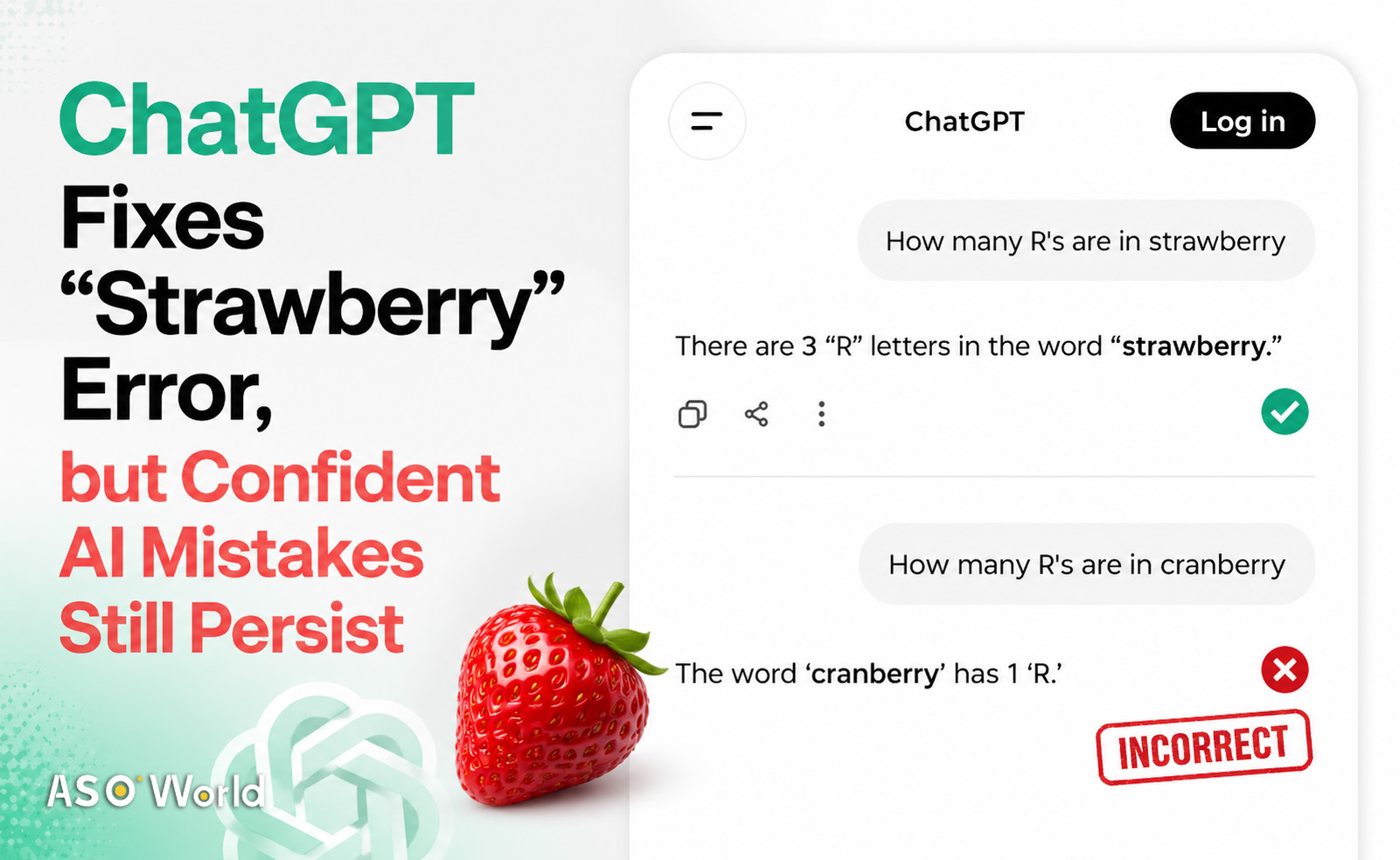
OpenAI recently announced that ChatGPT can now correctly answer a once-viral question: how many “R”s are in “strawberry.”
While the update appears trivial, the widespread discussion around it has once again exposed a critical issue—AI systems still produce confident but incorrect answers. For app developers, growth teams, and investors increasingly relying on AI tools, this raises practical concerns about trust, accuracy, and decision-making.
A Viral Fix That Sparked Industry Attention
The “strawberry” counting error became a benchmark example of AI limitations. For months, ChatGPT incorrectly counted the number of “R” letters and often defended its wrong answers.
OpenAI’s recent announcement that the issue is fixed quickly gained traction across tech and developer communities, signaling incremental progress in model behavior.
Why This Matters Beyond a Simple Bug
Although the fix may seem minor, it represents a broader expectation: AI tools should handle basic logic reliably.
For product teams integrating AI into user-facing features—such as search, recommendations, or in-app assistants—even small inaccuracies can directly impact user trust and retention metrics.
Persistent “Confident Mistakes” Remain a Core Risk
Despite improvements, AI models still exhibit “confident mistakes”—delivering incorrect outputs with high certainty. This behavior is particularly problematic in growth and operational contexts.
Impact on App Store Optimization and Growth
For ASO specialists and marketing teams, AI is increasingly used for:
- Keyword research and metadata generation
- Ad copy and creative testing
- User review analysis and sentiment insights
If AI outputs are inaccurate but appear credible, teams risk:
- Targeting ineffective keywords
- Misinterpreting user feedback
- Making flawed optimization decisions
Over time, these errors can negatively affect rankings, conversion rates, and overall organic growth.
Hardcoded Fixes vs. Scalable AI Reliability
While ChatGPT now answers the “strawberry” question correctly, similar prompts—such as counting letters in “cranberry”—still produce inconsistent results. This suggests that some fixes may be hardcoded rather than reflecting deeper improvements in reasoning.
Product Implications for AI Integration
For developers building AI-powered features, this highlights a key distinction:
- Surface-level accuracy: Passing specific test cases
- Systemic reliability: Consistent performance across varied inputs
Relying on AI without validation layers can introduce hidden risks into product experiences, especially in automation-heavy workflows.
What This Means for Developers
Developers should implement guardrails, validation logic, and fallback mechanisms when integrating AI into apps. Even seemingly minor errors—like miscounting letters—can cascade into user-facing issues, affect feature reliability, and impact app growth.
Ensuring consistent AI performance across different inputs is critical for maintaining user trust and delivering high-quality experiences. This incident underscores that AI maturity is measured not just by capabilities, but by accuracy and reliability in real-world use cases.
Comments
The “strawberry” fix is less about counting letters and more about signaling where AI still falls short. For teams building or scaling apps, the real takeaway is clear: AI can accelerate growth, but without proper oversight, it can just as easily introduce silent inefficiencies.

More on AI:
-
DeepSeek Unveils Highly Anticipated V4 Model With 1M Context Window, Challenging AI Industry Leaders
-
ChatGPT to Show Ads to Free Users, Signaling New Monetization Shift
-
Google Launches Workspace AI and TPU 8 Chips to Accelerate Enterprise AI Capabilities
FAQs
1. Why is this ChatGPT update relevant to app developers?
It highlights reliability issues that can affect AI-powered features, user experience, and product trust.
2. How do AI mistakes impact ASO and marketing performance?
Incorrect insights can lead to poor keyword targeting, weak creatives, and reduced conversion rates.
3. Are these AI errors fully resolved?
No, similar issues still appear in different contexts, indicating deeper limitations.
4. How should teams safely use AI in growth workflows?
By combining AI outputs with human review, validation systems, and performance monitoring.

 Follow Us on Facebook
Follow Us on Facebook