DeepSeek has released the preview version of its DeepSeek-V4 model series, marking a significant upgrade in context length, architecture efficiency, and cost structure. The release includes two variants—V4-Pro and V4-Flash—both supporting a 1 million token context window while targeting different performance and efficiency needs.
Core Model Specifications and Architecture
DeepSeek-V4 combines large-scale parameter design with efficient activation mechanisms to balance performance and computational cost.

(Source: DeepSeek)
Architecture Efficiency and MoE Design
Both models adopt a Mixture-of-Experts (MoE) approach, where only a subset of parameters is activated during inference.
- V4-Pro activates 49B out of 1.6T parameters
- V4-Flash activates 13B out of 284B
This significantly reduces inference cost while maintaining strong reasoning performance. Combined with training on over 30 trillion tokens, the models demonstrate robust general knowledge and multi-step reasoning capabilities.
Detailed Model Specifications
For a clearer understanding of the different capabilities and configurations of the DeepSeek-V4 models, here's a detailed breakdown of their specifications:
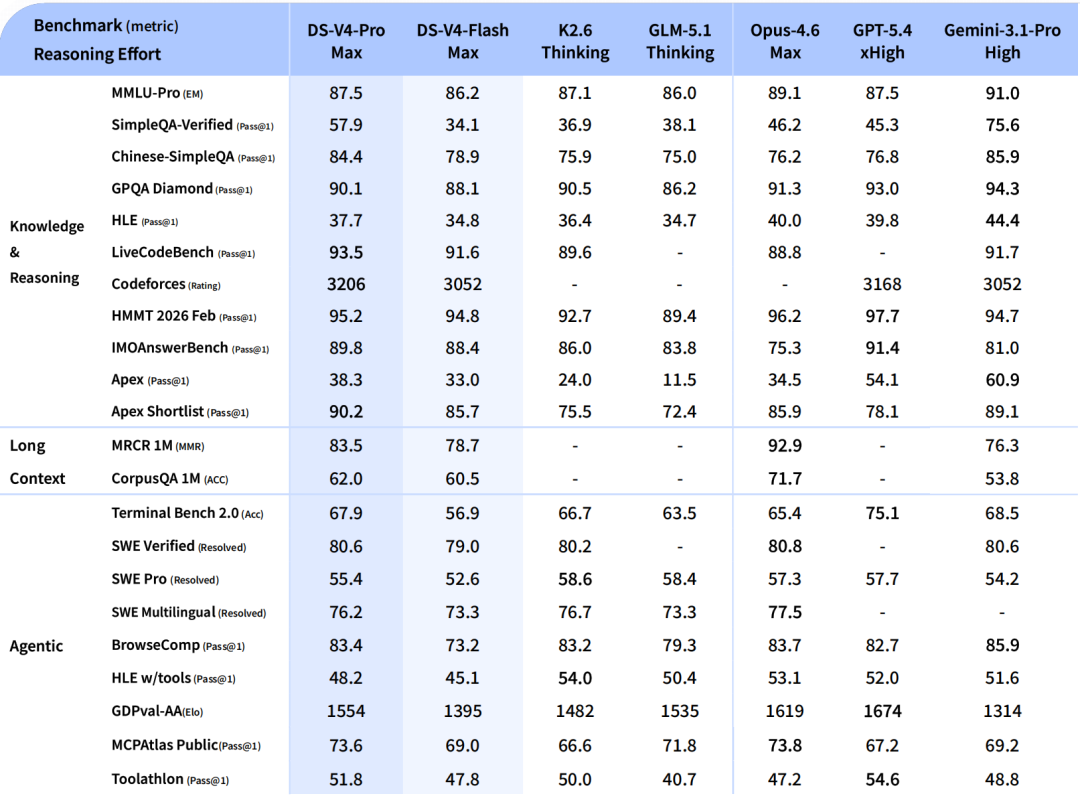
(Source: DeepSeek)
Pricing, Context Scale, and Performance Trade-offs
A key highlight from the release is the aggressive pricing aligned with efficiency gains:
- V4-Flash:
- Input (cache hit): 0.2 RMB / million tokens
- Input (cache miss): 1 RMB / million tokens
- Output: 2 RMB / million tokens
- V4-Pro:
- Input (cache hit): 1 RMB / million tokens
- Input (cache miss): 12 RMB / million tokens
- Output: 24 RMB / million tokens
Both models support up to 1M context input and 384K max output, making them suitable for long-form reasoning and large-scale processing tasks.
Why 1M Context Matters
The extended context window enables:
- Full-document and multi-document reasoning
- Persistent long conversations
- Codebase-level understanding
- Complex agent workflows
This significantly expands usability compared to typical short-context models.
Product Positioning and Developer Access
Deployment and Access Capabilities
Both models support:
- Open-source availability
- API access (OpenAI-compatible and Anthropic-compatible endpoints)
- Web and app-based usage
- Tool calling and JSON output
- Context continuation and FIM (Fill-in-the-Middle, limited to non-reasoning mode)
Practical Use Cases
- V4-Pro (Expert Mode):
Designed for complex reasoning, enterprise workflows, and high-accuracy outputs - V4-Flash (Fast Mode):
Optimized for speed, real-time applications, and cost-sensitive deployments
This dual-model strategy allows developers to choose based on latency, cost, and task complexity.
Competitive Positioning in the AI Ecosystem
DeepSeek continues to position itself as a cost-efficient alternative to leading proprietary models from OpenAI and Google. Compared to earlier models like DeepSeek V3.2, which was released to challenge models such as GPT-5 and Gemini, the V4 series takes the next step by focusing on scalable deployment, lower inference cost, and practical developer usability.
👉For a deeper dive into how DeepSeek V3.2 sets the stage for this leap, check out our previous article, DeepSeek Launches V3.2 AI Models to Challenge GPT-5 and Gemini.
Additionally, the DeepSeek V4 model is also a response to the ongoing trends in AI development, as highlighted in our earlier article, DeepSeek Prepares Advanced Coding-Focused AI Model Set for Mid-February Release, where we discussed how the company’s new releases were designed to boost performance in specialized domains, including advanced coding tasks.

Comments
The DeepSeek-V4 release signals a transition in AI competition—from maximizing raw model size to optimizing efficiency, cost, and usability. The combination of ultra-long context, MoE architecture, and flexible pricing suggests future differentiation will increasingly depend on deployment economics and developer adoption rather than benchmark dominance.
FAQ
1. What is the difference between total and activated parameters?
Total parameters represent the full model size, while activated parameters are the subset used during inference to reduce computation cost.
2. How do V4-Pro and V4-Flash differ?
V4-Pro focuses on deeper reasoning and accuracy, while V4-Flash prioritizes speed and lower cost.
3. What advantages does a 1M token context provide?
It enables processing of long documents, complex workflows, and extended conversations in a single session.
4. Are DeepSeek-V4 models suitable for developers?
Yes, they support API integration, open-source deployment, and multiple usage modes for different application scenarios.

 Follow Us on Facebook
Follow Us on Facebook