





Googleは公式に、AIを搭載したいくつかの製品や機能を、Google I/O 2024 イベントで発表しました。この革新的な技術は、私たちの働き方や様々なプラットフォームでのAIとの関わり方を革新することになります。
概要
Google I/O 2024は、AI技術の進化における転換点となりました。その舞台では、 サンダー・ピチャイ がGoogleの未来のビジョンを発表しました。
このイベントでは、GoogleのマルチモーダルAIモデルであるジェミニの変革的な可能性が様々なプラットフォームで披露されました。
AI概要やAsk Photosを使った検索体験の革新から、Google Workspaceでの知的なメール要約による生産性向上まで、GoogleはAIがユーザーとのインタラクションをどのように変えているかを示しました。
(クレジット: Google)
また、AIエージェントの導入は、買い物から引っ越しまで、日常のタスクをサポートする未来を示唆しました。
イノベーションと共に、GoogleはAIの責任ある使用にコミットし、AI支援型レッドチーミングや拡張されたSynthIDなどの措置を導入して、AI技術の倫理的な使用を確保しました。
Google I/O 2024は、技術の進化だけでなく、開発者とユーザーの協力によってより役立ち、責任あるAIエコシステムを形作る取り組みも強調しました。
グーグル ジェミニ

GoogleのGeminiモデルファミリーは、以下のようないくつかの更新を導入します:
1. Gemini 1.5 Flash: この軽量モデルは、マルチモーダルな推論能力と拡張されたコンテキストウィンドウを備え、速度と効率が最適化されています。これにより、要約、チャットアプリケーション、長文書類からのデータ抽出など、さまざまなタスクで優れた性能を発揮します。
2. Gemini 1.5 Pro:強化された論理推論、マルチターン会話、音声と画像理解を備えた、大幅に改良されたモデルです。これにより、2百万トークンのコンテキストウィンドウをサポートし、より複雑なタスクが可能となりました。
3. Gemini Nano: テキストだけでなく、画像も含めることで、視覚、音声、話し言葉を通じて世界をより良く理解できるようになりました。
4. 次世代のオープンモデル(Gemma 2):Gemma 2は、革新的な性能と効率性を備えた責任あるAIイノベーションのために設計されています。また、PaLI-3に触発された初のビジョン言語モデルであるPaliGemmaを紹介します。
5. AIアシスタントの進化(プロジェクトAstra):プロジェクトAstraは、複雑でダイナミックな状況に理解し、対応できる、積極的で個人的なAIアシスタントを開発することを目指しています。ジェミニの進歩を活用することで、これらのアシスタントは情報をより速く処理し、より会話形式で応答することができます。
これらの更新は、AI技術の重要な進歩を示し、AIモデルが何を達成できるかの境界を押し広げています。
Google Photos: GeminiによるAsk Photos
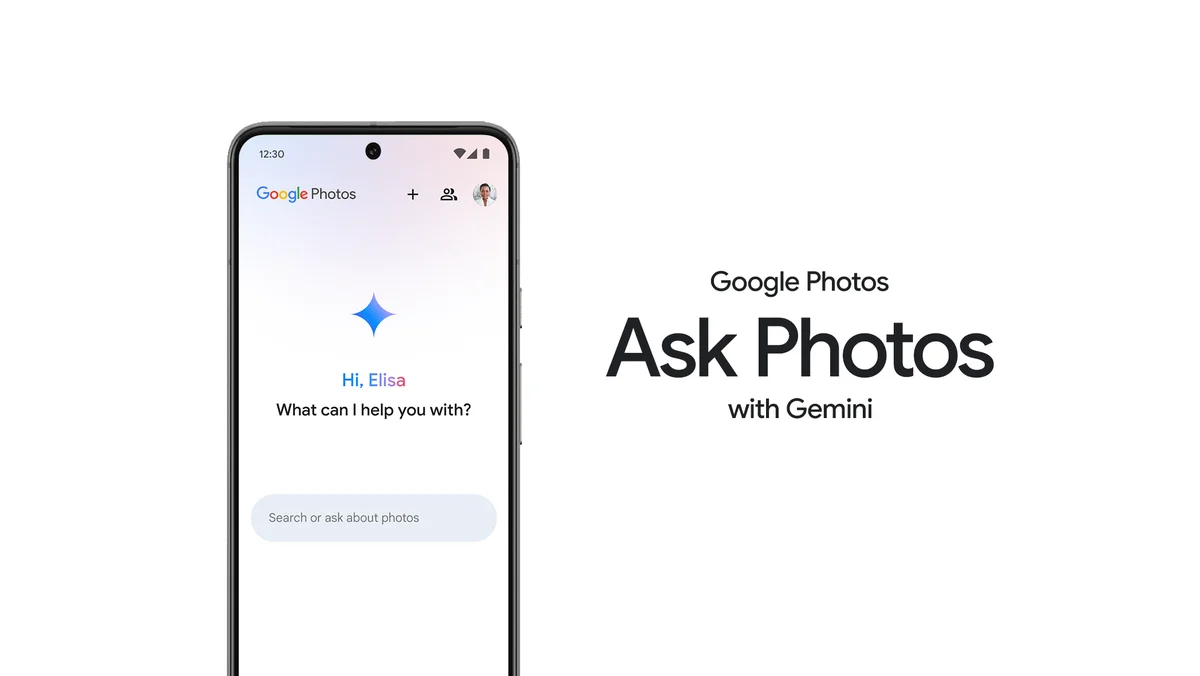
(クレジット: Google)
Ask Photosは、Google Photosの新しい実験的な機能で、Gemini AIモデルで動作します。
これにより、ユーザーは「私が訪れた各国立公園から最高の写真を表示してください」といった自然な言語の質問で、特定の写真や情報を簡単に検索できます。
高度なマルチモーダル能力を使用して、Ask Photosは写真のコンテンツを分析し、誕生日パーティーのテーマなどの詳細を認識することさえできます。
プライバシーに焦点を当て、Googleは個人データを広告に使用せず、Ask Photosを写真コレクションを管理するための便利で安全なツールにしています。
検索における生成AI
Google検索は、生成AIの導入により、情報のナビゲーションを容易にする大きな進化を遂げました。
カスタマイズされたGeminiモデルにより、検索は今、AI概要を提供し、トピックの要約と関連リンクを付け加えます。
これらのAI概要は、検索ラボの実験で数十億回の成功した使用例が示すように、時間を節約し、ユーザー満足度を高めるために設計されています。
今週から、AI概要はアメリカのユーザーに展開され、年末までに世界展開の計画があります。
ユーザーは、概要の詳細レベルを調整し、一度の検索で複雑な質問をすることができ、アクセシビリティと効率性が向上します。
たとえば、ユーザーはボストンのベーコンヒルからイントロオファーとウォーキングタイムを持つ最高のヨガスタジオを見つけるといった詳細なクエリを行うことができます。
検索はまた、食事や休暇の計画を支援し、近々、AIによる結果ページの組織化を提供します。
ビデオ理解の進化により、ビデオを使用した検索が可能になり、トラブルシューティングや情報収集がより視覚的になります。これらのイノベーションにより、Google検索はよりスマートで直感的になりました。
>>> グーグル、AI検索結果をオプトイン非対応ユーザーにも拡大
VideoFX、ImageFX、およびMusicFX
GoogleはVideoFXを導入しました。ImageFXおよびMusicFX向けの新機能も追加されました。
>>> レビュー: グーグル、ラボのImageFXとMusicFXでAIスイートを拡張
VideoFXはlabs.googleからの最新の実験で、その高度な生成ビデオモデルVeoによってビデオ作成を革新しています。テキストのプロンプトだけで、ユーザーはアイデアを魅力的なビデオクリップに変換し、映画の効果や音楽の伴奏を含めることができます。
ImageFXは今、高度な編集コントロールを提供し、ユーザーが画像の特定の要素を簡単に操作できるようになりました。
さらに、最新の画像生成モデルであるImagen 3は、写真現実主義とテキストレンダリングを向上させます。
MusicFXはDJモードを導入し、ユーザーがビートとジャンルを容易にミックスしてダイナミックな音楽ストーリーを作成できるようにします。
これらの更新は、Googleが責任ある生成AIを前進させることに取り組みながら、ユーザーが自らの創造性を本質的に表現できるようにすることを反映しています。
新しい生成メディアモデルとツール
ビデオジェネレーター: Veo
VeoはGoogleの最新のビデオ生成技術の突破口です。言語と視覚の正確な理解により、素晴らしい1080pのビデオを生成し、比類のない創造的な制御を提供します。
マルチステップ推論などの機能により、Veoは一貫したリアルな映像を作成し、映画製作者Donald Gloverとのコラボレーションを通じて実証されています。
画像ジェネレーター: Imagen 3
Imagen 3は信じられないほどの詳細とリアリティを持つ写真を生成します。
自然な言語を理解し、画像を向上させるための細かい詳細を組み込みます。Imagen 3は、選択されたクリエーター向けに提供されるImageFXで利用可能です。
学習モデル: LearnLM

(Credit: Google)
LearnLMは、学習のより魅力的で個人的な、そして有用な体験にするために、生成AIを活用したGoogleの新しいモデルの一族です。
教育研究に基づいており、LearnLMは、アクティブラーニングのインスピレーション、認知負荷の管理、そして学習者のニーズへの適応などの原則を組み込んでいます。
>>> 教育アプリケーススタディ
Googleは、Search、YouTube、およびGeminiなどの既存の製品にLearnLMを統合し、よりインタラクティブで個人的な学習体験を可能にします。
さらに、Googleは、研究論文をオーディオ会話に分解するIlluminateや、多様なメディアを通じた自己ペースの学習のためのプラットフォームであるLearn Aboutなどの新しいツールを試験導入しています。
教育者や教育機関とのパートナーシップを通じて、Googleは教育におけるAIの利点を最大化し、潜在的なリスクに対処しています。
AI開発のためのツール
GoogleはAI開発のためのオープンなエコシステムのツールを提供しています:
-
Keras: TensorFlow、PyTorch、またはJAXの上でワークフローを実行するためにKerasを使用します。
-
Keras on ColabでLoRAを使用する: モデルを簡単に微調整します。
-
OpenXLA: トレーニングスピードを向上させます。
-
RAPIDS cuDF: Colabでのワークロードの加速。
1. モバイル開発
GoogleはAndroid向けのAI強化体験を可能にすることに焦点を当てています:
> Android StudioのGemini: 高品質なAndroidアプリをより速く構築するために設計されています。
> Gemini Nano & AICore: 効率的なモデルをモバイルデバイスで直接実行し、低遅延の応答と強化されたデータプライバシーを実現します。
> Kotlin Multiplatform(KMP) on Android: 開発者は、AndroidのKMPのファーストクラスサポートを活用して、アプリのビジネスロジックをプラットフォーム間で共有することで生産性を向上させることができます。
> Jetpack Compose: Jetpack Composeは、Android向けに見栄えの良い適応型ユーザーエクスペリエンスを構築するためのツールを提供しています。
関連記事:
>>> Google I/O 2024: Google Play のアプリとゲームに関する開発者の主な見解
2. ウェブ開発
Googleは、より良いウェブ開発のためのツールを提供しています:
> ChromeのGemini Nano: ChromeデスクトップでのWebGPU、WebAssembly、およびGemini Nanoの統合でオンデバイスAIを統合します。
> スペキュレーションルールAPI: より速く、シームレスなブラウジング体験のためのページの事前取得と事前レンダリングを可能にします。
> マルチページサイト向けのView Transitions API: さまざまなウェブサイトアーキテクチャ間でスムーズで流動的なナビゲーション体験を解除します。
> Chrome DevToolsコンソールの洞察: Googleは、Chrome DevToolsコンソール内でのAIパワードの洞察を紹介し、デバッグプロセスを効率化します。
3. フルスタック、マルチプラットフォーム開発
Googleは、AIパワーのフルスタックアプリの構築、テスト、および出荷のためのツールを提供しています:
> FlutterとDartのアップデート: FlutterとDartは、パフォーマンスとサポートの向上のためにアップデートされます。
> 現代のAIパワーアプリ向けにFirebaseを進化させる: Firebaseは、PostgreSQLデータベース接続、GitHubからのスムーズなデプロイ、およびGemmaモデルとのAI機能をサポートするようになりました。
> Checks: GoogleのAIパワーのコンプライアンスプラットフォーム、Checksは、アプリのプライバシーとコンプライアンスのワークフローを簡素化します。
Gemini API & 開発者コンペティション

ジェミニAPI開発者コンペティション(Gemini API Developer Competition)は、すべてのレベルの開発者にAIの未来を形作る機会を提供します。
Gemini APIを自分のアプリケーションに統合することで、開発者は実世界の課題に取り組み、より良い未来に貢献することができます。
チューニング、システム命令、およびJSONモードなどの機能により、Google AI StudioのGemini APIを使用して、強力なGeminiモデルでプロトタイプを作成し、ビルドすることが簡単になります。
"詳細な情報、賞品、カテゴリー、リソース、および公式ルールについては、ai.google.dev/competitionをご覧ください。
このコンペティションは2024年8月12日まで開催されます。終了後、お気に入りのアプリに投票して、People's Choice賞を受賞することができます!"
AIセーフティ&誤用回避
AI支援のレッドチーム活動とエキスパートフィードバック
Googleは最先端の研究と人間の専門知識を組み合わせて、Geminiなどのモデルを強化しています。彼らは、Google DeepMindのゲームの突破口に触発された「AI支援のレッドチーム活動」を導入しています。
これには、AIエージェントを相互に競争させ、レッドチーム活動の能力を拡大するというものが含まれます。
Googleは、敵対的プロンプトの対処と問題のある出力の制限を通じて、モデルの精度と信頼性を向上させることを目指しています。
また、内部のセキュリティ専門家と独立した専門家からのフィードバックも統合され、モデルのパフォーマンスをさらに向上させます。
AIテキスト&ビデオウォーターマーク: SynthID

(Credit: Google)
モデルの出力がよりリアルになるにつれて、GoogleはSynthIDという技術を導入し、AI生成の画像や音声に認識しやすいウォーターマークを追加して、誤用から保護します。
今年、GoogleはSynthIDをテキストとビデオに拡張し、デジタルコンテンツの起源を理解することを促進する幅広い投資の一環としています。
保護策の共同作業
GoogleはAIの責任ある使用を確保するためにエコシステムと協力することを約束しています。今後数ヶ月で、GoogleはSynthIDテキストウォーターマーキングを彼らの更新された責任ある生成AIツールキットを通じてオープンソース化する予定です。
さらに、GoogleはAdobe、Microsoft、スタートアップなどと協力して、デジタルメディアの透明性を向上させる標準を確立するコンテンツの証明性と真正性のための連合(C2PA)のメンバーです。

 Follow Us on Facebook
Follow Us on Facebook
