






OpenAIの12日間のイベントの最終日に、OpenAIは最新のAIモデルであるO3とO3-miniを発表しました。これは、以前のO1 "reasoning"モデルからの重要な進歩を示しています。
これらのモデルは、特定の条件下での推論能力を向上させ、AGIの限界に近づくことを目指しています。
これらのモデルは現在、安全性のテストが可能であり、2025年初頭により広範なリリースが予定されています。
OpenAI O3とは何ですか?
O3モデルファミリーには、よりコンパクトなO3-miniも含まれており、コーディング、数学、および一般的な知能の複雑なタスクに取り組むために設計されています。
OpenAIは「deliberative alignment」という概念を導入して安全性と信頼性を向上させ、モデルが「私的な思考の連鎖」を使用してタスクを推論することを可能にしました。
O3とO1の比較
O3モデルは、高度な推論能力を備えたO1モデルからの重要な進化を示しています。O1モデルは推論タスクのための基礎を築いた一方、O3はより複雑な問題をより高い精度と効率で処理するように設計されています。
これは、「私的な思考の連鎖」を取り入れることで実現され、モデルがタスクの計画と推論をより効果的に行うことができます。
コーディングパフォーマンス
(出典: OpenAI)
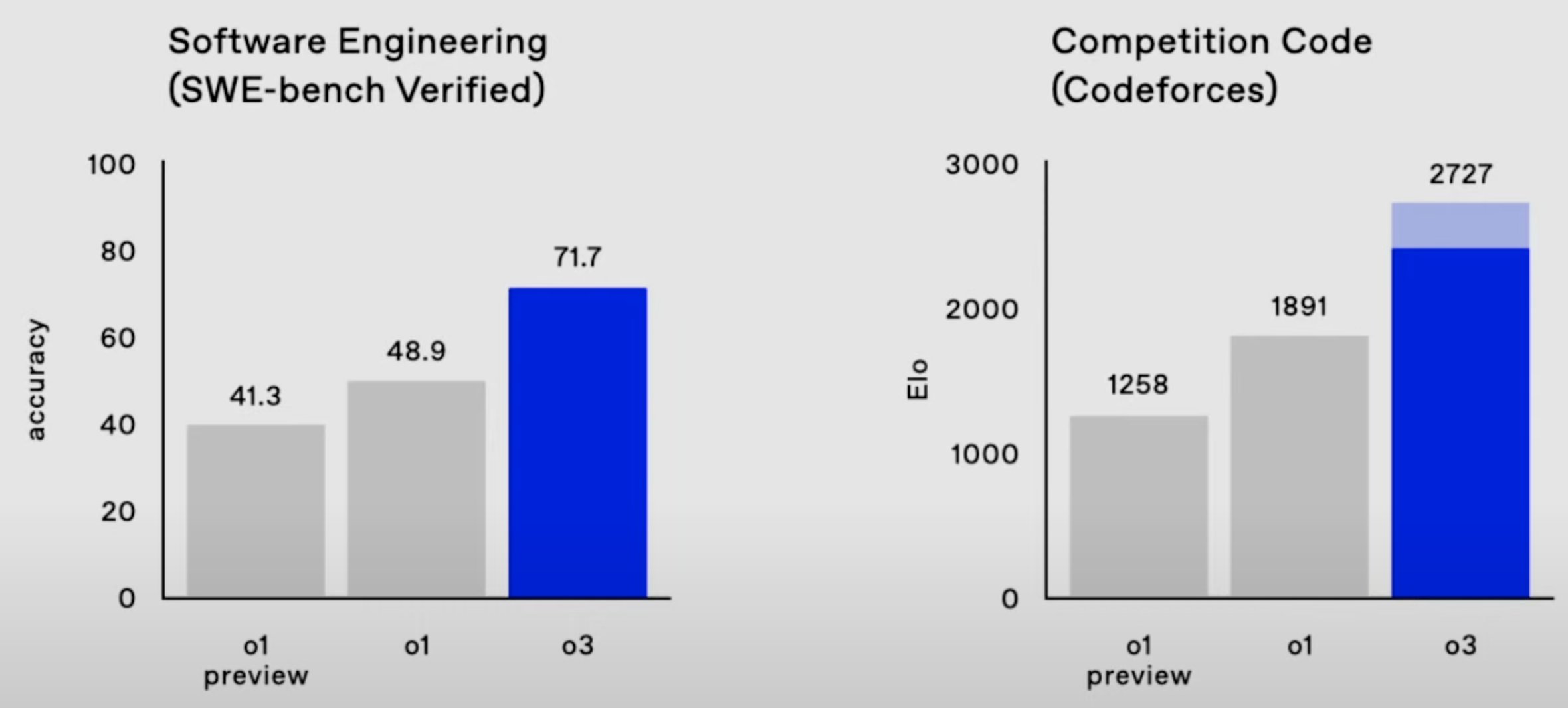
コーディングタスクでは、O3はO1に比べて大幅な改善が見られます。
実世界のソフトウェアタスクを評価するSWE-Bench Verifiedベンチマークでは、O3は71.7%の正確性を達成し、O1を上回りました。
さらに、競技プログラミングでは、O3は1891のスコアを叩き出したO1に対し、2727のELOスコアを達成しています。これはO3が複雑なコーディング課題に取り組む能力が高いことを示しています。
数学的推論パフォーマンス
(出典: OpenAI)
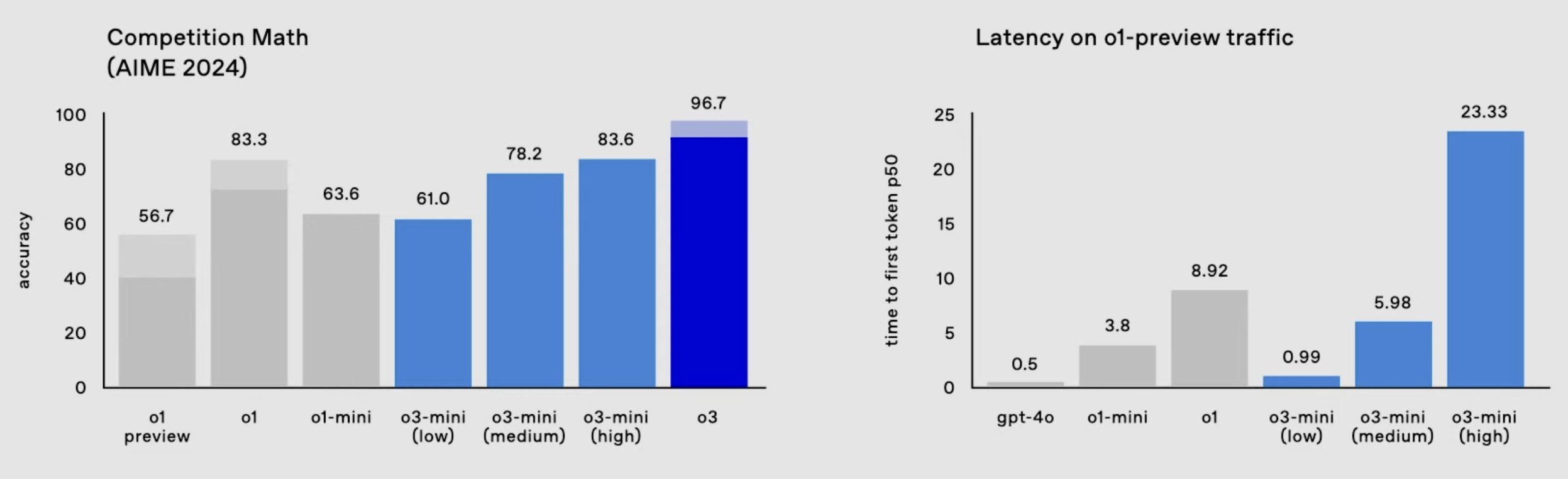
O3は数学的推論でもO1を上回っています。
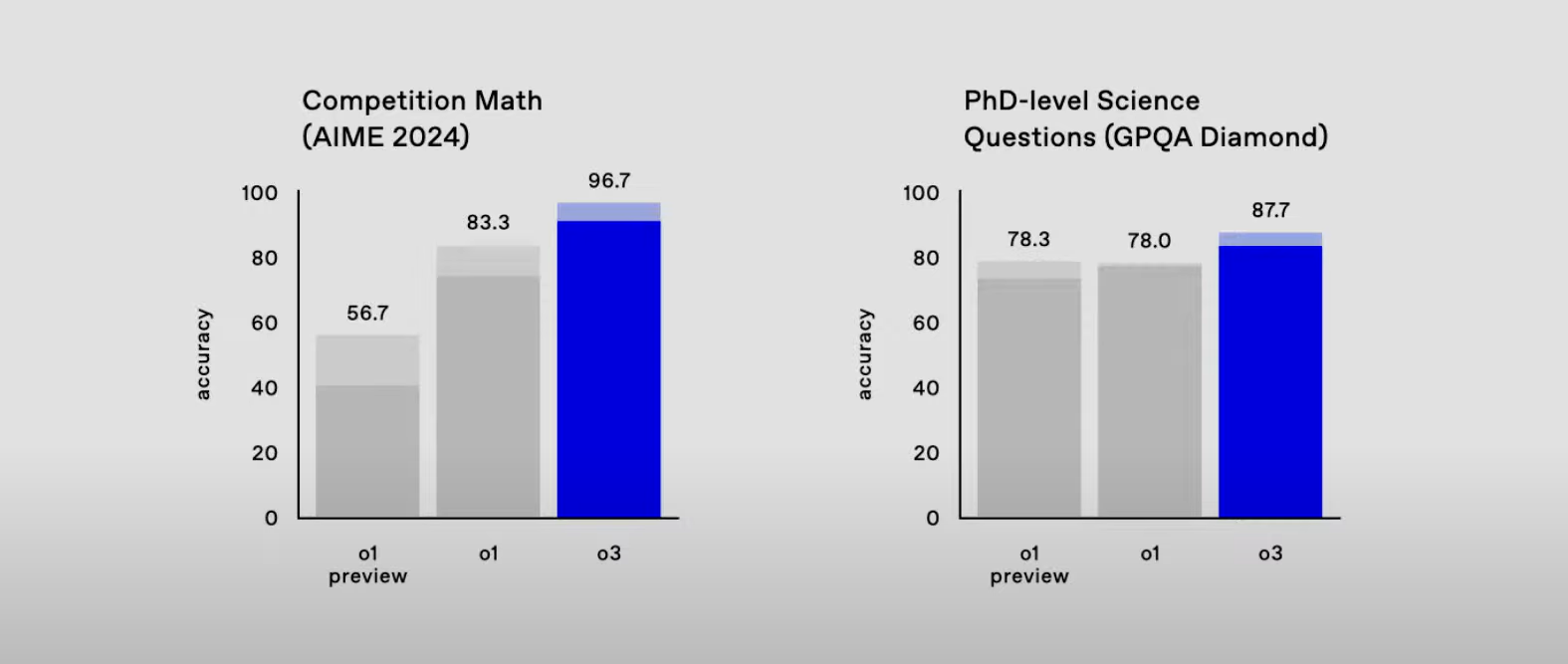
American Invitational Mathematics Exam (AIME) 2024では、O3は印象的な96.7%を獲得し、わずか一つの問題を誤りましたが、O1は83.3%でした。
この改善は、O3が複雑な数学の問題に対処する能力が向上し、人間レベルのパフォーマンスに近づいていることを示しています。
一般科学パフォーマンス
(出典: OpenAI)
一般科学と知能の領域では、O3が大学レベルの科学問題を含むGPQA Diamondなどの評価においてO1を上回っています。
O3は87.7%の正確性を達成し、O1の78%を上回ります。これはO3が様々な科学的分野で技術的に要求の高い問題を解決する能力が高まっていることを示しています。
推論と安全機能
O3は、タスクの複雑さに基づいてモデルの「思考時間」を調整できる「adjustable reasoning time」の概念を導入しています。これはO1には存在しない機能です。
さらに、O3は「deliberative alignment」という概念を使用して、O1よりも効果的に提示を評価し、潜在的なリスクを特定することで安全性を向上させています。
まとめると、O3はコーディング、数学、一般的な知能の分野でO1に比べて重要な進歩を遂げており、推論と安全機能が向上しています。これにより、複雑な問題解決タスクにおいてより強力かつ多目的なツールとなっています。
O3のリリース日と入手方法
O3とO3-miniは現在安全性テストのために利用可能であり、O3-miniは2025年1月末までにリリースされる予定であり、その後にO3がリリースされます。この慎重なリリースは、OpenAIが責任を持ってAIの展開を行う姿勢を示しています。
編集者コメント
O3とO3-miniモデルは、有望なベンチマーク結果を持つAI推論能力の重要な進展を示しています。
ただし、実世界での適用性はまだ評価されていません。
OpenAIの段階的なリリースと安全性テストへの注力は、先進的なAI技術の展開における課題を反映しています。
これらのモデルはAGIの実現への道のりで重要な役割を果たし、将来のイノベーションの舞台を設定する可能性があります。

 Follow Us on Facebook
Follow Us on Facebook



