DeepSeekは、コンテキスト長、アーキテクチャ効率、コスト構造において大幅なアップグレードを実現したDeepSeek-V4モデルシリーズのプレビュー版をリリースしました。今回のリリースには2つのバリアント—V4-ProおよびV4-Flash—が含まれ、いずれも100万トークンのコンテキストウィンドウをサポートしながら、異なるパフォーマンスおよび効率ニーズに対応しています。
コアモデル仕様とアーキテクチャ
DeepSeek-V4は、大規模なパラメータ設計と効率的なアクティベーション機構を組み合わせ、性能と計算コストのバランスを実現しています。

(出典:DeepSeek)
アーキテクチャ効率とMoE設計
両モデルはMixture-of-Experts(MoE)アプローチを採用しており、推論時にはパラメータの一部のみが有効化されます。
- V4-Proは1.6Tのうち49Bのパラメータを有効化
- V4-Flashは284Bのうち13Bを有効化
これにより、強力な推論性能を維持しながら推論コストを大幅に削減します。さらに、30兆トークン以上でのトレーニングと組み合わせることで、幅広い一般知識と多段階推論能力を発揮します。
詳細モデル仕様
DeepSeek-V4モデルの異なる機能と構成をより明確に理解するため、以下にその仕様の詳細な内訳を示します。
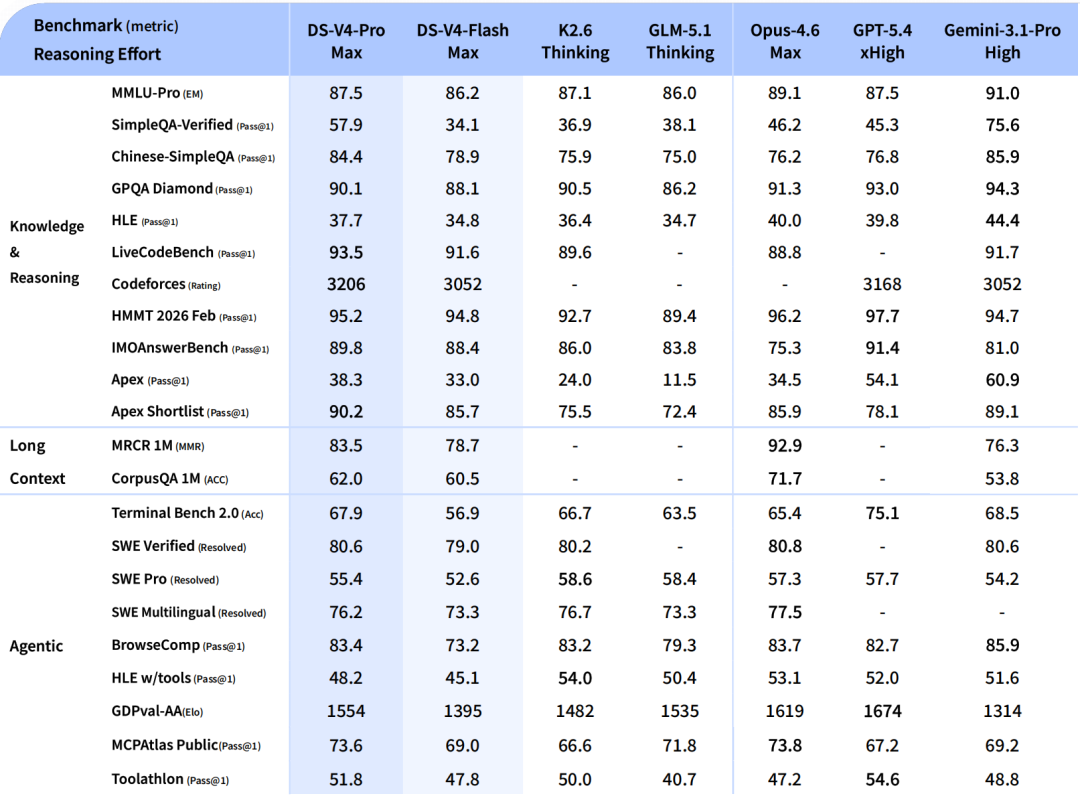
(出典:DeepSeek)
価格、コンテキスト規模、および性能のトレードオフ
今回のリリースにおける重要なポイントの一つは、効率向上に合わせた積極的な価格設定です:
- V4-Flash:
- 入力(キャッシュヒット):100万トークンあたり0.2人民元
- 入力(キャッシュミス):100万トークンあたり1人民元
- 出力:100万トークンあたり2人民元
- V4-Pro:
- 入力(キャッシュヒット):100万トークンあたり1人民元
- 入力(キャッシュミス):100万トークンあたり12人民元
- 出力:100万トークンあたり24人民元
両モデルは100万トークンのコンテキスト入力および最大384K出力をサポートしており、長文推論や大規模処理タスクに適しています。
なぜ100万コンテキストが重要なのか
拡張されたコンテキストウィンドウにより、以下が可能になります:
- ドキュメント全体および複数ドキュメントの推論
- 継続的な長時間会話
- コードベースレベルの理解
- 複雑なエージェントワークフロー
これにより、一般的な短コンテキストモデルと比較して実用性が大幅に向上します。
製品ポジショニングと開発者アクセス
デプロイメントおよびアクセス機能
両モデルは以下をサポートします:
- オープンソース提供
- APIアクセス(OpenAI互換およびAnthropic互換エンドポイント)
- Webおよびアプリベースでの利用
- ツール呼び出しおよびJSON出力
- コンテキスト継続およびFIM(Fill-in-the-Middle、非推論モードに限定)
実用的なユースケース
- V4-Pro(エキスパートモード):
複雑な推論、エンタープライズワークフロー、高精度出力向けに設計 - V4-Flash(高速モード):
速度、リアルタイムアプリケーション、コスト重視の導入向けに最適化
このデュアルモデル戦略により、開発者はレイテンシー、コスト、タスクの複雑さに応じて選択できます。
AIエコシステムにおける競争ポジション
DeepSeek-V4は、AIシステムにおけるコスト効率重視のスケーリングへの広範な移行を反映しています。従来モデルと比較して、V4シリーズは以下を重視しています:
- MoEによる低推論コスト
- 開発者向けのスケーラブルな展開
- ベンチマーク重視の設計よりも実用性を優先
ピーク性能の追求だけに焦点を当てるのではなく、DeepSeekはV4を実世界のアプリケーション向けソリューションとして位置づけ、オープンソースとプロプライエタリAIモデルのギャップを縮めています。
コメント
DeepSeek-V4のリリースは、AI競争が単なるモデル規模の最大化から、効率性、コスト、実用性の最適化へと移行していることを示しています。超長コンテキスト、MoEアーキテクチャ、柔軟な価格設定の組み合わせは、今後の差別化がベンチマークでの優位性よりも、導入経済性と開発者採用にますます依存することを示唆しています。
FAQ
1. 総パラメータ数と有効化パラメータ数の違いは何ですか?
総パラメータ数はモデル全体の規模を示し、有効化パラメータは計算コストを削減するために推論時に使用される一部のパラメータを指します。
2. V4-ProとV4-Flashの違いは何ですか?
V4-Proはより深い推論と高精度に重点を置き、V4-Flashは速度と低コストを優先します。
3. 100万トークンのコンテキストにはどのような利点がありますか?
長文ドキュメント、複雑なワークフロー、長時間の会話を単一セッションで処理できるようになります。
4. DeepSeek-V4モデルは開発者に適していますか?
はい、API統合、オープンソースでの展開、さまざまなアプリケーションシナリオに対応する複数の利用モードをサポートしています。

 Follow Us on Facebook
Follow Us on Facebook