






アリババは、OpenAIのDeep Research などの主要AIシステムと競合するために設計された新しい大規模言語モデル、Tongyi DeepResearchを発表しました。
このリリースは、コスト意識の高い企業、研究機関、高度な生産性ユーザー向けに、アリババがグローバルAI市場での影響力を拡大しようとする重要な一歩です。
Tongyi DeepResearchとは?
Tongyi DeepResearchは、アリババクラウドのTongyi Labが開発したオープンソースのAIエージェントで、2025年9月17日に正式にリリースされました。
大規模言語モデル(LLM)として設計され、マルチステップのウェブリサーチ、レポート作成、複雑なクエリ解決など、長期的な深い情報探索タスクに最適化されています。
消費者向けチャットボットとは異なり、Tongyi DeepResearchは研究レベルの知能、技術的精度、コスト効率を重視しています。その位置付けは、学術、金融、医療、その他のデータ集約型産業で働くプロフェッショナルに明確に焦点を当てています。
このモデルは、合計305億パラメータを持つMixture-of-Experts(MoE)アーキテクチャに基づいて構築されており、トークンごとに30億~33億のパラメータのみがアクティブです。この設計により、パフォーマンスを損なうことなく高い計算効率を実現しています。
特筆すべきは、アリババがモデル全体、トレーニングパイプライン、推論フレームワークを GitHub および Hugging Face で完全に公開し、独自システムと競合する初の完全オープンソースのウェブエージェントとした点です。
(アリババ Tongyi DeepResearch GitHubページ)
主な機能と能力
知能(ベンチマーク)
Tongyi DeepResearchは、専門的なエージェントベンチマークで最先端のスコアを達成しています。
xbench-DeepSearch(75.0)、BrowseComp-ZH(46.7)、GAIA(70.9)でリードし、特に中国語の情報検索とドメイン固有の推論で強みを発揮しています。
BrowseComp-ENでは35.3を記録し、エージェントワークフローでOpenAIを32%上回る一方、OpenAIやAnthropicのような独自モデルが約88~90%の精度を維持する一般的なMMLUスタイルの評価では後れを取っています。
要するに、Tongyiの知能は、広範な消費者向けタスクではなく、研究と事実の深さに特化しています。
コスト効率
Tongyi DeepResearchは、Apache 2.0ライセンスの下でオープンソースモデルとしてリリースされているため、開発者や企業にとって無料で利用可能です。
この寛容なライセンスは、完全な商用利用、カスタマイズ、展開を許可します。
モデルはHugging Face、GitHub、またはアリババのModelScopeプラットフォームを介してダウンロードして実行できます。
モデル自体は無料ですが、APIプロバイダーはホストアクセスに対して料金を課す場合があります。
たとえば、OpenRouterでは、Tongyi DeepResearch 30B A3Bモデルの価格は入力トークン100万あたり0.09ドル、出力トークン100万あたり0.45ドルとされています。
この料金は、Google GeminiやAnthropic Claudeなどの独自の競合他社(通常、100万トークンあたり数ドル)よりも大幅に低く、研究集約型のワークロードにおいて最もコスト効率の高いオプションの一つです。
コンテキストウィンドウ
Tongyiは128,000トークンのコンテキストウィンドウをサポートし、GPT-4oと同等ですが、Geminiの100万~200万トークンには及びません。
Geminiの規模で超長編文書を処理することはできませんが、128Kは文献レビュー、規制遵守、大規模データセットクエリなどのエンタープライズ級の研究タスクに十分です。
速度と展開
Mixture-of-Experts(MoE)アーキテクチャを採用したTongyiは、低レイテンシで高速なスループットを維持します。
控えめなハードウェアで推定スループットは1秒あたり100トークンを超え、最初のトークン生成までの時間は1秒未満です。
重いインフラを必要とする独自システムとは異なり、Tongyiの軽量な設計により、コンシューマPCでの展開が可能で、研究グループや中小企業にとってのアクセシビリティが向上します。
規模とアクセシビリティ
Tongyi DeepResearchは、合計305億パラメータで動作し、クエリごとに30億がアクティブで、OpenAIやGoogleの兆単位のパラメータモデルよりもはるかに小規模です。
それにもかかわらず、Tongyiはエージェントベンチマークでほぼ同等のパフォーマンスを提供します。
最も重要なのは、GPT、Gemini、ClaudeのクローズドAPIとは対照的に、GitHubおよびHugging Faceで完全にオープンソースである点です。
このオープン性により、開発者はエコシステムに縛られることなくカスタム研究エージェントを構築できます。
主要競合との比較
(出典: アリババ Tongyi DeepResearch GitHubページ)
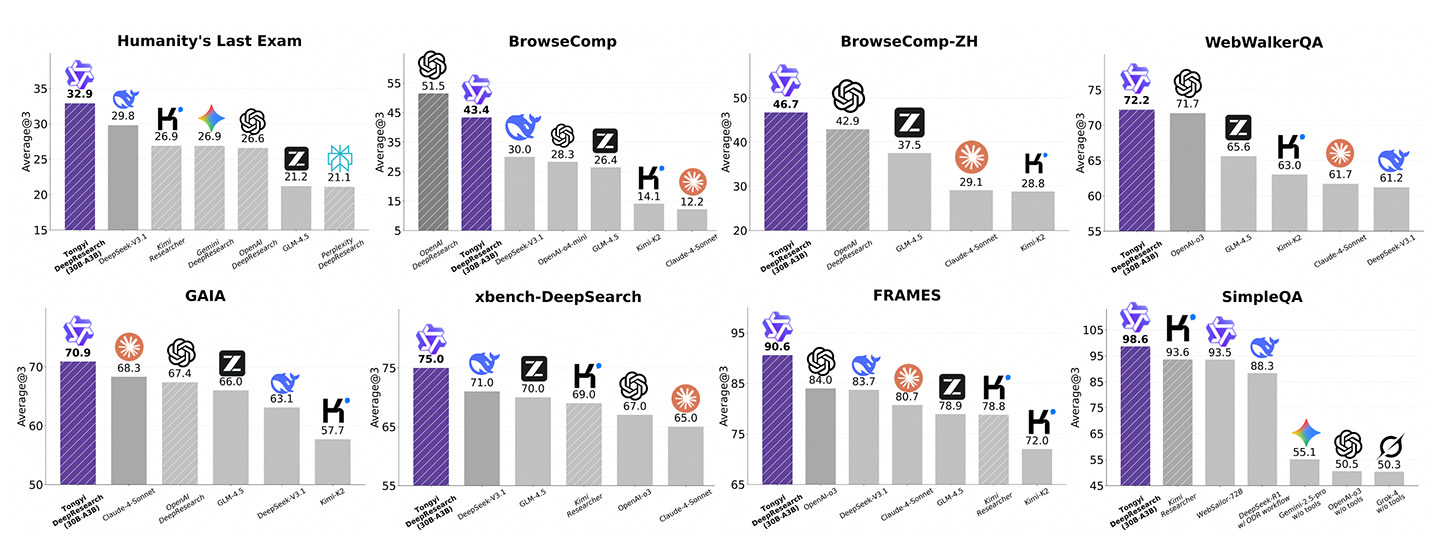
独立した評価に基づくベンチマーク結果は、OpenAI DeepResearch、Gemini、DeepSeek、Claudeなどに対するTongyi DeepResearchのパフォーマンスを強調しています:
-
Humanity's Last Exam: Tongyi 32.9、DeepSeek V3.1(29.8)、Gemini DeepResearch(26.9)、OpenAI DeepResearch(26.6)を上回る。
-
BrowseComp(英語): OpenAI DeepResearchが51.5でリード、Tongyiは43.4で続き、DeepSeek V3.1(30.0)を上回る。
-
BrowseComp-ZH(中国語): Tongyiが46.7でリード、OpenAI DeepResearch(42.9)、GLM-4.5(37.5)を上回る。
-
WebWalkerQA: Tongyi 72.2、OpenAI-03(71.7)をわずかに上回り、GLM-4.5(65.6)を大きく上回る。
-
GAIA: Tongyi 70.9、Claude-4-Sonnet(68.3)、OpenAI DeepResearch(67.4)を上回る。
-
xbench-DeepSearch: Tongyi 75.0、DeepSeek V3.1(71.0)、GLM-4.5(70.0)、OpenAI-03(67.0)をリード。
-
FRAMES: Tongyi 90.6、OpenAI-03(84.0)、DeepSeek V3.1(83.7)を大きく上回る。
-
SimpleQA: Tongyi 98.6、Kimi Researcher(93.6)、Websailor-72B(93.5)を大きく上回り、Geminiは55.1、OpenAI-03は50.5。
全体として、Tongyi DeepResearchは8つのベンチマークタスクのうち7つで1位にランクインしました。最大の強みは、中国語理解、事実の検索、シンプルなQ&Aにあります。
OpenAIは英語のブラウジングで優位性を維持していますが、Geminiは研究ベンチマーク全体で大きく遅れています。
これらの結果は、特に西洋のモデルにまだギャップがある多言語コンテキストで、アリババが企業や研究重視のアプリケーションを支配する戦略を強調しています。

編集者のコメント
アリババのTongyi DeepResearchは、LLM競争のシフトを示しています—クローズドな消費者向けチャットボットから、オープンな研究グレードのシステムへ。
その強力なベンチマークスコア、オープンソースライセンス、低コストのアクセシビリティは、特に企業や学術界にとって非常に魅力的です。
一部の英語ブラウジングタスクでは遅れを取っていますが、研究ベンチマークと多言語の深さでの優位性により、Tongyiは西洋の既存企業に対する強力な挑戦者として位置付けられています。

 Follow Us on Facebook
Follow Us on Facebook



