DeepSeek выпустила предварительную версию серии моделей DeepSeek-V4, что стало значительным обновлением по длине контекста, эффективности архитектуры и структуре затрат. Релиз включает два варианта—V4-Pro и V4-Flash—оба поддерживают контекстное окно в 1 миллион токенов и ориентированы на разные требования к производительности и эффективности.
Основные характеристики модели и архитектура
DeepSeek-V4 сочетает крупномасштабный дизайн параметров с эффективными механизмами активации для балансировки производительности и вычислительных затрат.

(Источник: DeepSeek)
Эффективность архитектуры и дизайн MoE
Обе модели используют подход Mixture-of-Experts (MoE), при котором во время инференса активируется только часть параметров.
- V4-Pro активирует 49B из 1.6T параметров
- V4-Flash активирует 13B из 284B
Это значительно снижает стоимость инференса при сохранении высокой способности к рассуждению. В сочетании с обучением на более чем 30 триллионах токенов модели демонстрируют прочные общие знания и возможности многошагового рассуждения.
Подробные характеристики модели
Для более чёткого понимания различных возможностей и конфигураций моделей DeepSeek-V4 ниже приведена подробная разбивка их характеристик:
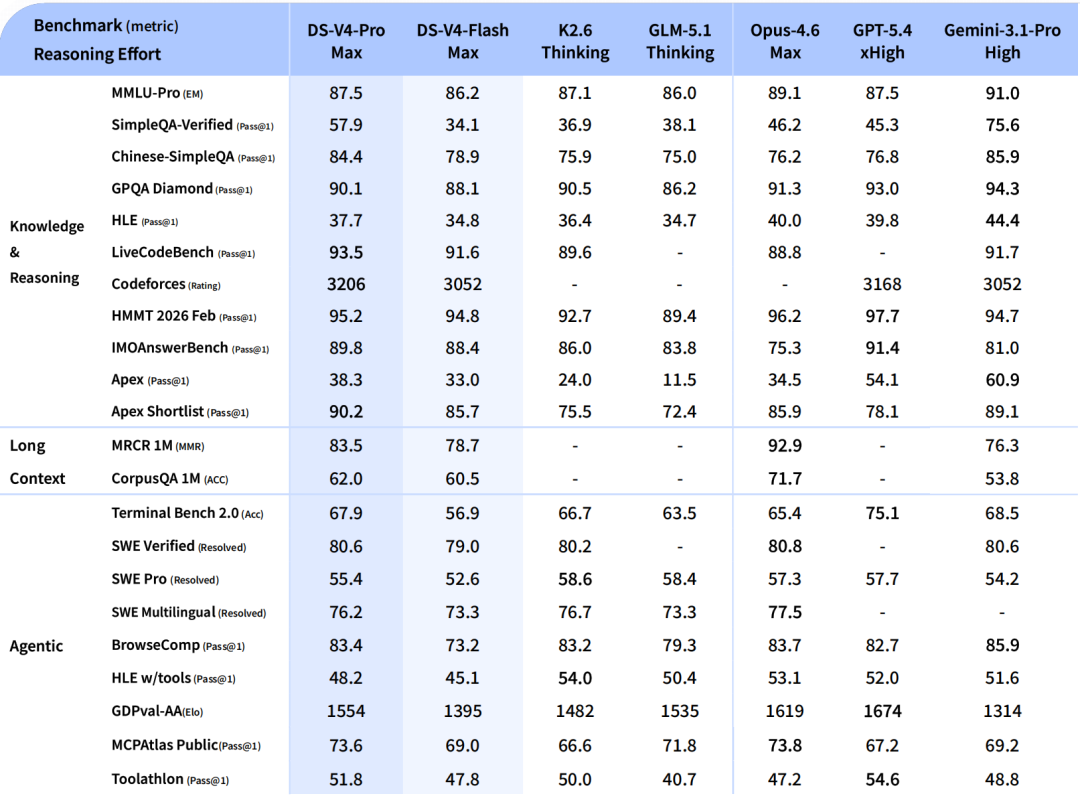
(Источник: DeepSeek)
Ценообразование, масштаб контекста и компромиссы производительности
Ключевым моментом релиза является агрессивная ценовая политика, соответствующая повышению эффективности:
- V4-Flash:
- Вход (попадание в кэш): 0.2 юаня / миллион токенов
- Вход (промах кэша): 1 юань / миллион токенов
- Выход: 2 юаня / миллион токенов
- V4-Pro:
- Вход (попадание в кэш): 1 юань / миллион токенов
- Вход (промах кэша): 12 юаней / миллион токенов
- Выход: 24 юаня / миллион токенов
Обе модели поддерживают до 1M входного контекста и 384K максимального выхода, что делает их подходящими для задач длинных рассуждений и крупномасштабной обработки.
Почему важен контекст в 1M
Расширенное контекстное окно позволяет:
- Анализировать целые документы и несколько документов одновременно
- Поддерживать длительные диалоги
- Понимать кодовые базы целиком
- Реализовывать сложные агентные рабочие процессы
Это значительно расширяет возможности использования по сравнению с типичными моделями с коротким контекстом.
Позиционирование продукта и доступ для разработчиков
Возможности развертывания и доступа
Обе модели поддерживают:
- Доступность с открытым исходным кодом
- Доступ через API (совместимые с OpenAI и Anthropic эндпоинты)
- Использование через веб и приложения
- Вызов инструментов и вывод в формате JSON
- Продолжение контекста и FIM (Fill-in-the-Middle, ограничено нережимом рассуждения)
Практические сценарии использования
- V4-Pro (Экспертный режим):
Предназначена для сложных рассуждений, корпоративных рабочих процессов и высокоточных результатов - V4-Flash (Быстрый режим):
Оптимизирована для скорости, приложений в реальном времени и сценариев с чувствительностью к стоимости
Эта стратегия двух моделей позволяет разработчикам выбирать решение в зависимости от задержки, стоимости и сложности задач.
Конкурентное позиционирование в экосистеме ИИ
DeepSeek-V4 отражает более широкий сдвиг в сторону экономически эффективного масштабирования ИИ-систем. По сравнению с предыдущими версиями серия V4 делает акцент на:
- Снижении стоимости инференса благодаря MoE
- Масштабируемом развертывании для разработчиков
- Практической применимости вместо ориентации только на бенчмарки
Вместо сосредоточения исключительно на пиковой производительности DeepSeek позиционирует V4 как решение для реальных приложений, сокращая разрыв между моделями с открытым исходным кодом и проприетарными ИИ-моделями.
Комментарии
Релиз DeepSeek-V4 сигнализирует о переходе в конкуренции ИИ — от максимизации «сырого» размера модели к оптимизации эффективности, стоимости и удобства использования. Сочетание сверхдлинного контекста, архитектуры MoE и гибкой ценовой политики указывает на то, что дальнейшая дифференциация будет всё больше зависеть от экономики развертывания и принятия разработчиками, а не от доминирования в бенчмарках.
FAQ
1. В чем разница между общим количеством и активированными параметрами?
Общее количество параметров отражает полный размер модели, тогда как активированные параметры — это подмножество, используемое во время инференса для снижения вычислительных затрат.
2. Чем отличаются V4-Pro и V4-Flash?
V4-Pro ориентирована на более глубокие рассуждения и точность, тогда как V4-Flash делает приоритетом скорость и более низкую стоимость.
3. Какие преимущества дает контекст в 1M токенов?
Он позволяет обрабатывать длинные документы, сложные рабочие процессы и продолжительные диалоги в рамках одной сессии.
4. Подходят ли модели DeepSeek-V4 для разработчиков?
Да, они поддерживают интеграцию через API, развертывание с открытым исходным кодом и несколько режимов использования для различных сценариев применения.

 Follow Us on Facebook
Follow Us on Facebook