At the 2026 Cloud Next conference, Google introduced Workspace Intelligence alongside its eighth-generation Tensor Processing Units—TPU 8t for training and TPU 8i for inference. These developments mark a major step in enterprise AI, offering advanced context-aware automation, rapid model training, and efficient inference performance. Businesses and developers can now leverage these tools to streamline workflows, analyze organizational data, and accelerate AI deployment.
Workspace Intelligence: Context-Aware AI Across Google Apps
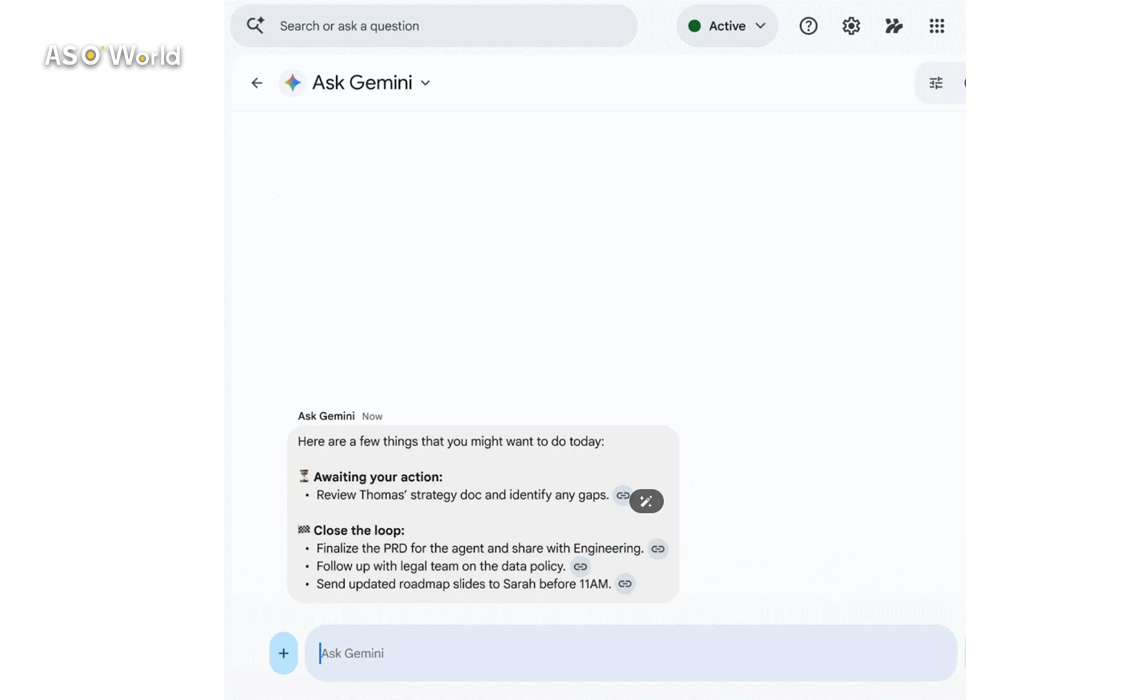
Key Functionalities by Application
Workspace Intelligence connects Gmail, Docs, Sheets, Slides, and Chat, creating a unified AI layer that understands complex organizational context. By analyzing project data, emails, meetings, and team interactions, it allows AI to assist with tasks automatically and contextually.
- Gmail: Automatically prioritizes emails, summarizes threads, and surfaces key actions.
- Google Docs: Generates infographics and charts from business data, edits multiple images for consistency, categorizes and responds to comments, and can revise content based on feedback.
- Google Slides: Produces full presentations aligned with company templates and visual guidelines, incorporating relevant project context.
- Google Sheets: Supports conversational data analysis and AI-assisted spreadsheet creation and updates.
- Google Chat (Ask Gemini): Handles tasks like generating documents and presentations, searching files based on descriptions, scheduling meetings considering team availability, and integrating with tools like Asana, Jira, and Salesforce.
Enhancing Efficiency and Personalization
Workspace Intelligence does not only automate tasks but learns user behavior, preferred formats, and communication style. This ensures outputs are both accurate and personalized, saving time and reducing manual errors across organizational workflows.
Enterprise Implications
- Reduced Manual Workload: Teams spend less time on repetitive tasks.
- Faster Decision-Making: AI surfaces relevant information and insights at the right time.
- Seamless Collaboration: Integration across multiple apps ensures that team context is preserved in outputs.
TPU 8t and 8i: High-Performance AI Hardware
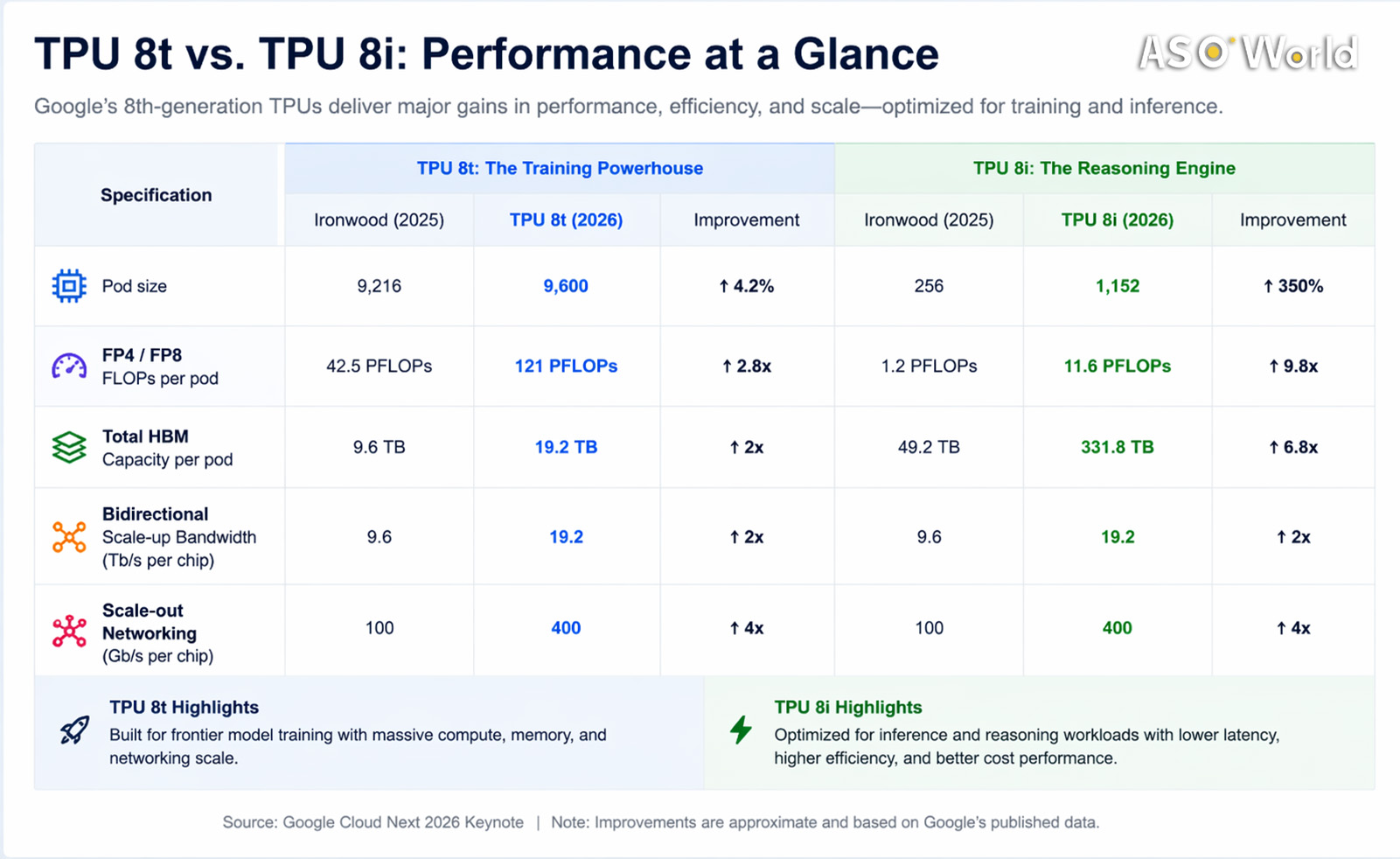
TPU 8t – Optimized for Model Training
- Purpose: Dedicated to efficiently building frontier AI models. Separating training from inference allows Google to optimize hardware specifically for large-scale computation.
- Performance Improvements: Compared to TPU 7, TPU 8t offers 124% more performance per watt and 2.8× better cost-efficiency.
- Scale & Memory: Supports superpods of up to 9,600 chips and 2 PB shared high-bandwidth memory. Chip-to-chip bandwidth is nearly doubled.
- New Capabilities:
- 121 ExaFlops computational power
- 10× faster storage access
- Near-linear scaling across up to 1 million chips using Virgo network with JAX and Pathways
- Application Scenario: Enables training of massive AI models for natural language processing, image recognition, and predictive analytics in weeks instead of months.
TPU 8i – Optimized for Model Inference
- Purpose: Handles model deployment, real-time reasoning tasks, and agentic AI workloads efficiently.
- Performance Improvements: 117% more performance per watt and 80% better performance per dollar compared to TPU 7.
- Memory & Latency Enhancements: 288 GB high-bandwidth memory combined with 384 MB on-chip SRAM (3× previous generation) minimizes idle time. Boardfly architecture reduces network diameter over 50%; chip-level collective acceleration engine reduces latency up to 5×.
- Application Scenario: Supports large-scale inference tasks, serving more users at lower cost and enabling real-time AI applications such as intelligent assistants, automated summaries, and predictive analytics.

(image credits: Google Cloud)
Why Two Separate Chips?
- 8t for Training: Focused on large-scale computation, optimizing memory and compute resources for developing complex models.
- 8i for Inference: Optimized for speed, efficiency, and cost-effectiveness in applying models to real-world tasks.
- Rationale: Separating training and inference allows Google to maximize hardware efficiency and performance for each workload type.
Direct Value for Developers and Tech Teams
Accelerating AI Development
TPU 8t enables faster training of large AI models, allowing enterprises to experiment with advanced features, test multiple model variations, and deploy AI solutions more quickly.
Reducing Operational Costs
TPU 8i’s improved efficiency and cost-effectiveness mean businesses can run AI models at scale with lower energy and infrastructure costs, making high-performance AI accessible for real-time applications.
Streamlining Workflow and Data Utilization
Workspace Intelligence and Gemini provide automated insights from organizational data, prioritize tasks, and enhance collaboration, enabling better decision-making and operational efficiency.
Strategic Planning for AI Adoption
Understanding the capabilities and differences of TPU 8t/8i allows enterprises to plan AI infrastructure and deployment strategies effectively, ensuring the right resources are allocated to training versus inference workloads.
Comments
Google’s launch demonstrates a strategy to integrate context-aware AI with high-performance hardware, transforming enterprise workflows and AI deployment. Workspace Intelligence and Gemini enable smarter, personalized automation, while TPU 8t and 8i provide specialized, high-efficiency solutions for training and inference. The separation of chips highlights Google’s focus on workload optimization, and these advancements give enterprises the tools to accelerate AI development, improve operational efficiency, and deploy large-scale AI applications effectively.

FAQ
Q1: What tasks can Workspace Intelligence automate?
A1: Email prioritization, document and presentation creation, spreadsheet editing, summarization, and integration with project management tools.
Q2: How do TPU 8t and 8i differ?
A2: TPU 8t is optimized for training large AI models; TPU 8i is optimized for inference, enabling low-latency, cost-effective deployment.
Q3: Why does Google use two separate chips for training and inference?
A3: Specialized hardware maximizes efficiency and performance for distinct workloads, allowing high-scale training and low-latency inference.
Q4: What improvements do TPU 8 chips offer over previous generations?
A4: TPU 8t offers 124% more performance per watt and 2.8× better cost-efficiency; TPU 8i offers 117% more performance per watt and 80% better cost-efficiency.

 Follow Us on Facebook
Follow Us on Facebook