DeepSeek는 DeepSeek-V4 모델 시리즈의 프리뷰 버전을 출시하며 컨텍스트 길이, 아키텍처 효율성, 비용 구조 측면에서 중요한 업그레이드를 이루었습니다. 이번 출시는 서로 다른 성능 및 효율 요구를 충족하도록 설계된 두 가지 변형—V4-Pro와 V4-Flash—을 포함하며, 두 모델 모두 100만 토큰 컨텍스트 윈도우를 지원합니다.
핵심 모델 사양 및 아키텍처
DeepSeek-V4는 대규모 파라미터 설계와 효율적인 활성화 메커니즘을 결합하여 성능과 연산 비용의 균형을 맞춥니다.

(출처: DeepSeek)
아키텍처 효율성과 MoE 설계
두 모델 모두 추론 과정에서 일부 파라미터만 활성화되는 Mixture-of-Experts(MoE) 방식을 채택했습니다.
- V4-Pro는 1.6T 파라미터 중 490억 개를 활성화
- V4-Flash는 2840억 개 중 130억 개를 활성화
이를 통해 강력한 추론 성능을 유지하면서도 추론 비용을 크게 절감합니다. 30조 개 이상의 토큰으로 학습된 이 모델들은 견고한 일반 지식과 다단계 추론 능력을 보여줍니다.
상세 모델 사양
DeepSeek-V4 모델의 다양한 기능과 구성에 대한 이해를 돕기 위해, 아래에 상세 사양을 정리했습니다:
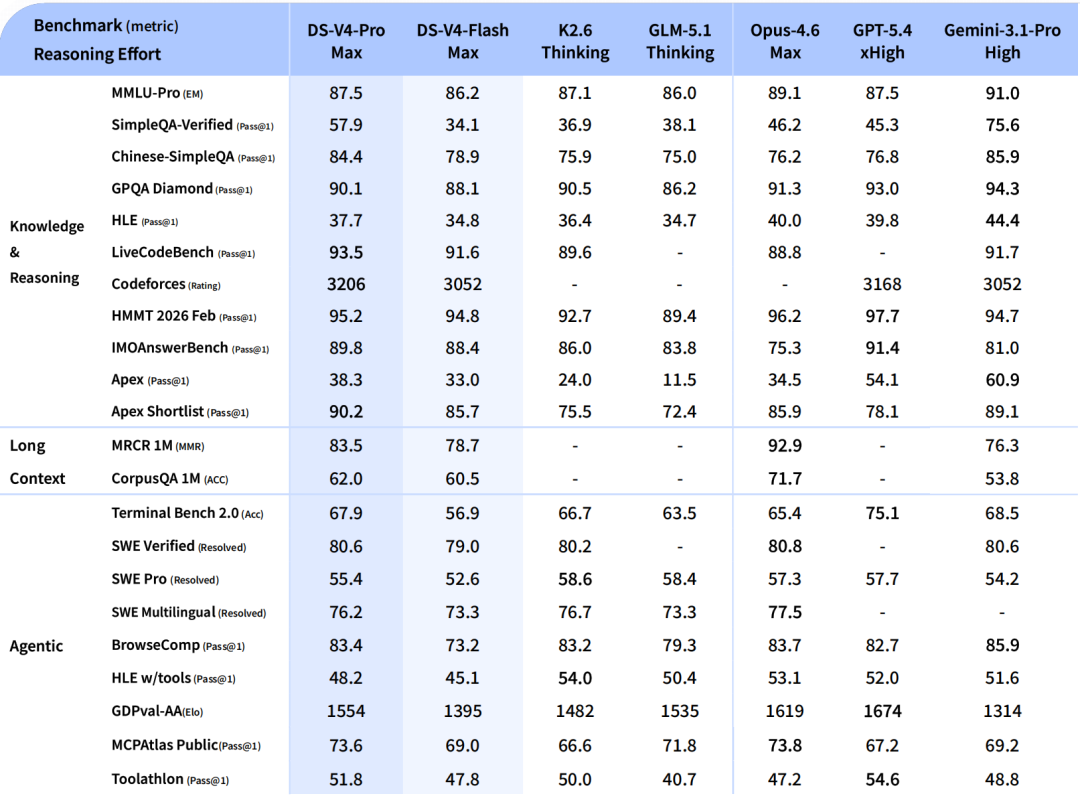
(출처: DeepSeek)
가격, 컨텍스트 규모 및 성능 트레이드오프
이번 출시의 핵심 특징 중 하나는 효율성 향상에 맞춘 공격적인 가격 정책입니다:
- V4-Flash:
- 입력 (캐시 적중): 100만 토큰당 0.2위안
- 입력 (캐시 미적중): 100만 토큰당 1위안
- 출력: 100만 토큰당 2위안
- V4-Pro:
- 입력 (캐시 적중): 100만 토큰당 1위안
- 입력 (캐시 미적중): 100만 토큰당 12위안
- 출력: 100만 토큰당 24위안
두 모델 모두 최대 100만 컨텍스트 입력과 최대 384K 출력을 지원하여 장문 추론 및 대규모 처리 작업에 적합합니다.
왜 100만 컨텍스트가 중요한가
확장된 컨텍스트 윈도우는 다음을 가능하게 합니다:
- 전체 문서 및 다중 문서 추론
- 지속적인 장기 대화
- 코드베이스 수준의 이해
- 복잡한 에이전트 워크플로
이는 일반적인 짧은 컨텍스트 모델과 비교해 활용성을 크게 확장합니다.
제품 포지셔닝 및 개발자 접근성
배포 및 접근 기능
두 모델 모두 다음을 지원합니다:
- 오픈소스 제공
- API 접근(OpenAI 호환 및 Anthropic 호환 엔드포인트)
- 웹 및 앱 기반 사용
- 툴 호출 및 JSON 출력
- 컨텍스트 이어쓰기 및 FIM(Fill-in-the-Middle, 비추론 모드에서만 제한적으로 지원)
실제 활용 사례
- V4-Pro (전문가 모드):
복잡한 추론, 엔터프라이즈 워크플로, 높은 정확도의 출력에 적합하도록 설계됨 - V4-Flash (고속 모드):
속도, 실시간 애플리케이션, 비용 민감형 배포에 최적화됨
이러한 이중 모델 전략은 개발자가 지연 시간, 비용, 작업 복잡도에 따라 선택할 수 있도록 합니다.
AI 생태계 내 경쟁 포지셔닝
DeepSeek-V4는 AI 시스템에서 비용 효율적 확장으로의 광범위한 전환을 반영합니다. 이전 버전과 비교해 V4 시리즈는 다음을 강조합니다:
- MoE를 통한 낮은 추론 비용
- 개발자를 위한 확장 가능한 배포
- 벤치마크 중심 설계보다 실용성 중시
최고 성능 수치에만 집중하기보다, DeepSeek는 V4를 실제 애플리케이션을 위한 솔루션으로 포지셔닝하며 오픈소스와 독점 AI 모델 간의 격차를 줄이고 있습니다.
댓글
DeepSeek-V4 출시는 AI 경쟁이 원시 모델 크기 극대화에서 효율성, 비용, 사용성 최적화로 전환되고 있음을 보여줍니다. 초장문 컨텍스트, MoE 아키텍처, 유연한 가격 정책의 결합은 향후 차별화 요소가 벤치마크 우위보다 배포 경제성과 개발자 채택에 점점 더 의존하게 될 것임을 시사합니다.
FAQ
1. 전체 파라미터와 활성화 파라미터의 차이는 무엇인가요?
전체 파라미터는 모델의 전체 크기를 의미하며, 활성화 파라미터는 연산 비용을 줄이기 위해 추론 시 사용되는 일부 파라미터를 의미합니다.
2. V4-Pro와 V4-Flash의 차이점은 무엇인가요?
V4-Pro는 더 깊은 추론과 정확성에 중점을 두며, V4-Flash는 속도와 낮은 비용을 우선시합니다.
3. 100만 토큰 컨텍스트의 장점은 무엇인가요?
단일 세션에서 장문 문서, 복잡한 워크플로, 장시간 대화를 처리할 수 있습니다.
4. DeepSeek-V4 모델은 개발자에게 적합한가요?
네, API 통합, 오픈소스 배포, 다양한 애플리케이션 시나리오를 위한 여러 사용 모드를 지원합니다.

 Follow Us on Facebook
Follow Us on Facebook