






알리바바는 OpenAI의 Deep Research와 같은 선도적인 AI 시스템과 경쟁하도록 설계된 새로운 대규모 언어 모델인 Tongyi DeepResearch를 공개했습니다.
이번 출시는 비용에 민감한 기업, 연구 기관, 고급 생산성 사용자를 목표로 알리바바가 글로벌 AI 시장에서 영향력을 확대하려는 중요한 단계입니다.
Tongyi DeepResearch란?
Tongyi DeepResearch는 알리바바 클라우드의 Tongyi Lab에서 개발한 오픈소스 AI 에이전트로, 2025년 9월 17일에 공식적으로 출시되었습니다.
대규모 언어 모델(LLM)로 설계된 이 모델은 다단계 웹 연구, 보고서 작성, 복잡한 쿼리 해결과 같은 장기적이고 심층적인 정보 탐색 작업에 최적화되어 있습니다.
소비자용 챗봇과 달리 Tongyi DeepResearch는 연구 수준의 지능, 기술적 정확성, 비용 효율성을 우선시합니다. 이 모델은 학계, 금융, 의료 및 기타 데이터 집약적 산업에서 일하는 전문가에 초점을 맞춘 명확한 포지셔닝을 보여줍니다.
이 모델은 총 305억 개의 파라미터를 가진 Mixture-of-Experts(MoE) 아키텍처를 기반으로 구축되었으며, 토큰당 30억~33억 개의 파라미터만 활성화됩니다. 이 설계는 성능 저하 없이 높은 계산 효율성을 보장합니다.
특히 알리바바는 모델 전체, 학습 파이프라인, 추론 프레임워크를 GitHub와 Hugging Face에서 완전히 공개하여 독점 시스템과 경쟁하는 최초의 완전 오픈소스 웹 에이전트로 자리 잡았습니다.
(알리바바 Tongyi DeepResearch GitHub 페이지)
주요 기능 및 성능
지능 (벤치마크)
Tongyi DeepResearch는 전문 에이전트 벤치마크에서 최첨단 점수를 달성했습니다.
xbench-DeepSearch(75.0), BrowseComp-ZH(46.7), GAIA(70.9)에서 선두를 달리며 특히 중국어 검색 및 도메인별 추론에서 강점을 보입니다.
BrowseComp-EN에서는 35.3점을 기록하며 에이전트 워크플로우에서 OpenAI를 32% 앞섰지만, OpenAI와 Anthropic과 같은 독점 모델이 약 88~90% 정확도를 유지하는 일반 MMLU 스타일 평가에서는 뒤처졌습니다.
요약하자면, Tongyi의 지능은 광범위한 소비자 작업보다는 연구와 사실적 깊이에 특화되어 있습니다.
비용 효율성
Tongyi DeepResearch는 Apache 2.0 라이선스 하에 오픈소스 모델로 출시되어 개발자와 기업에게 무료로 제공됩니다.
이 관대한 라이선스는 완전한 상업적 사용, 사용자 지정, 배포를 허용합니다.
이 모델은 Hugging Face, GitHub 또는 알리바바의 ModelScope 플랫폼을 통해 다운로드 및 실행할 수 있습니다.
모델 자체는 무료지만, API 제공업체는 호스팅 액세스에 대해 요금을 부과할 수 있습니다.
예를 들어, OpenRouter는 Tongyi DeepResearch 30B A3B 모델의 가격을 입력 토큰 100만 개당 0.09달러, 출력 토큰 100만 개당 0.45달러로 책정했습니다.
이 요금은 Google Gemini나 Anthropic Claude와 같은 독점 경쟁사의 비용(보통 백만 토큰당 몇 달러)에 비해 훨씬 낮으며, 연구 집약적 워크로드에 가장 비용 효율적인 옵션 중 하나로 자리 잡았습니다.
컨텍스트 윈도우
Tongyi는 128,000 토큰의 컨텍스트 윈도우를 지원하며, GPT-4o와 동등하지만 Gemini의 100만~200만 토큰에는 미치지 못합니다.
Gemini 규모의 초장편 문서를 처리할 수는 없지만, 128K는 문헌 검토, 규제 준수, 대규모 데이터셋 쿼리와 같은 엔터프라이즈급 연구 작업에 충분합니다.
속도 및 배포
Mixture-of-Experts(MoE) 아키텍처로 구축된 Tongyi는 낮은 지연 시간으로 빠른 처리량을 유지합니다.
보통 하드웨어에서 추정 처리량은 초당 100토큰을 초과하며, 첫 번째 토큰 생성 시간은 1초 미만입니다.
무거운 인프라를 요구하는 독점 시스템과 달리, Tongyi의 간결한 설계는 소비자 PC에서도 배포가 가능해 연구 그룹과 중소기업의 접근성을 높입니다.
규모 및 접근성
Tongyi DeepResearch는 총 305억 개의 파라미터로 작동하며, 쿼리당 30억 개가 활성화되어 OpenAI나 Google의 조 단위 파라미터 모델보다 훨씬 작습니다.
그럼에도 불구하고 Tongyi는 에이전트 벤치마크에서 거의 동등한 성능을 제공합니다.
가장 중요한 점은 GPT, Gemini, Claude의 폐쇄형 API와 달리 GitHub와 Hugging Face에서 완전 오픈소스라는 점입니다.
이 개방성은 개발자가 에코시스템 종속 없이 사용자 지정 연구 에이전트를 구축할 수 있게 합니다.
주요 경쟁자와의 비교
(출처: 알리바바 Tongyi DeepResearch GitHub 페이지)
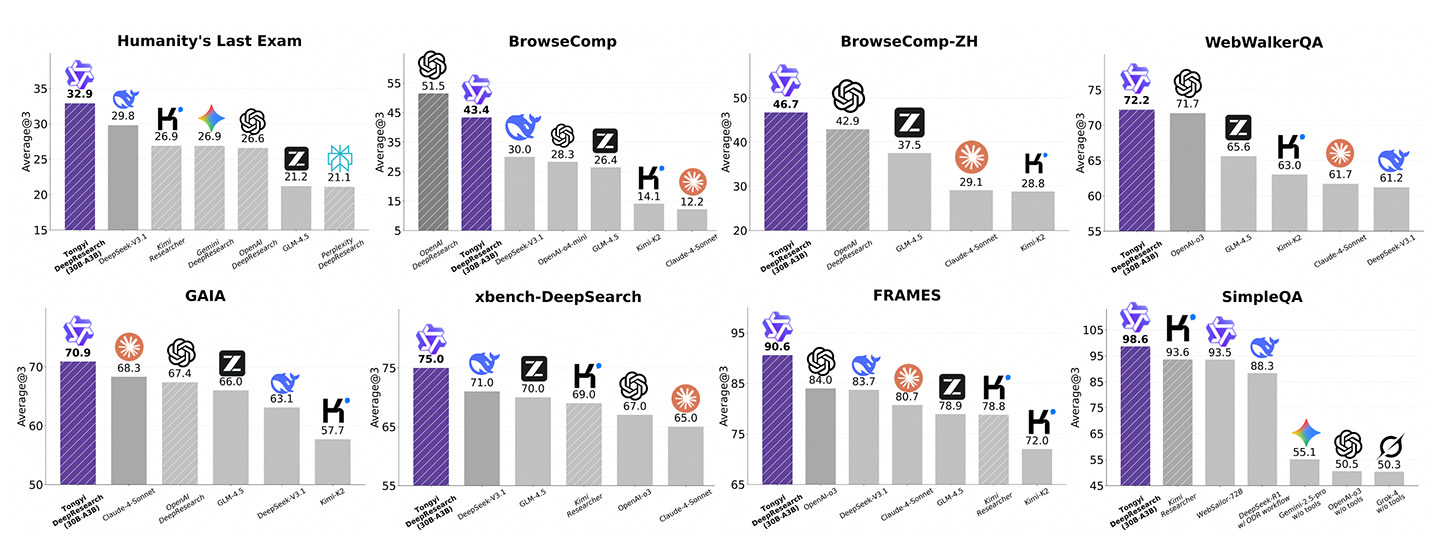
독립적인 평가에 기반한 벤치마크 결과는 OpenAI DeepResearch, Gemini, DeepSeek, Claude 등에 비해 Tongyi DeepResearch의 성능을 강조합니다:
-
Humanity's Last Exam: Tongyi 32.9, DeepSeek V3.1(29.8), Gemini DeepResearch(26.9), OpenAI DeepResearch(26.6)를 앞섭니다.
-
BrowseComp(영어): OpenAI DeepResearch가 51.5로 선두, Tongyi는 43.4로 뒤따르며 DeepSeek V3.1(30.0)을 앞섭니다.
-
BrowseComp-ZH(중국어): Tongyi가 46.7로 선두, OpenAI DeepResearch(42.9), GLM-4.5(37.5)를 앞섭니다.
-
WebWalkerQA: Tongyi 72.2, OpenAI-03(71.7)을 약간 앞서며 GLM-4.5(65.6)를 크게 앞섭니다.
-
GAIA: Tongyi 70.9, Claude-4-Sonnet(68.3), OpenAI DeepResearch(67.4)를 앞섭니다.
-
xbench-DeepSearch: Tongyi 75.0, DeepSeek V3.1(71.0), GLM-4.5(70.0), OpenAI-03(67.0)을 앞섭니다.
-
FRAMES: Tongyi 90.6, OpenAI-03(84.0), DeepSeek V3.1(83.7)을 크게 앞섭니다.
-
SimpleQA: Tongyi 98.6, Kimi Researcher(93.6), Websailor-72B(93.5)를 크게 앞서며, Gemini는 55.1, OpenAI-03은 50.5입니다.
전체적으로 Tongyi DeepResearch는 8개 벤치마크 작업 중 7개에서 1위를 차지했습니다. 가장 큰 강점은 중국어 이해, 사실 검색, 간단한 Q&A에 있습니다.
OpenAI는 영어 브라우징에서 우위를 유지하지만, Gemini는 연구 벤치마크 전반에서 상당히 뒤처집니다.
이 결과는 특히 서구 모델이 아직 부족한 다국어 컨텍스트에서 알리바바가 기업 및 연구 중심 애플리케이션을 지배하려는 전략을 강조합니다.

편집자의 코멘트
알리바바의 Tongyi DeepResearch는 LLM 경쟁의 변화를 나타냅니다—폐쇄형 소비자 챗봇에서 개방형 연구 등급 시스템으로.
강력한 벤치마크 점수, 오픈소스 라이선스, 저비용 접근성은 특히 기업과 학계에 매력적입니다.
일부 영어 브라우징 작업에서 뒤처지지만, 연구 벤치마크와 다국어 깊이에서 우위를 점하며 Tongyi는 서구의 기존 기업에 대한 강력한 도전자로 자리 잡았습니다.

 Follow Us on Facebook
Follow Us on Facebook



